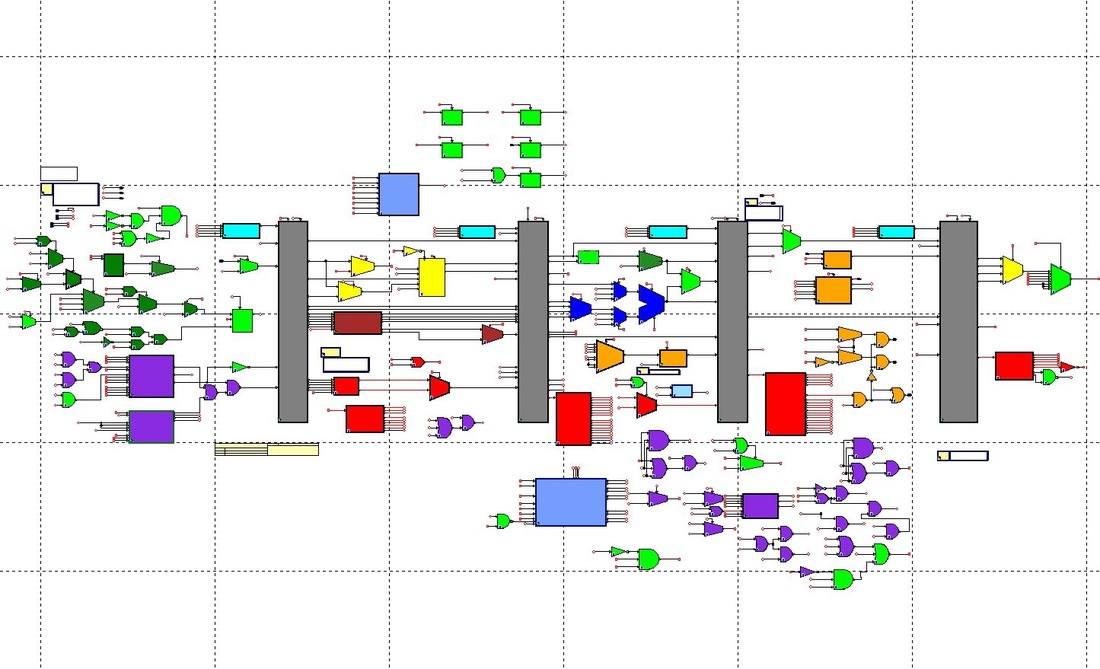
LC3b 5-Stage Pipeline Processor
For ECE 411: Computer Organization & Design, our final project involved designing a 5-stage pipeline processor with the LC3b instruction set architecture and cache integration. With two of my friends, ECE undergraduate students Megan Boivin and Luis Mendez, we managed to design a pipeline with the ability to implement every instruction (except RTI), data forwarding, and cache integration with memory stalling. The cache size was 2048 bits, with a line size of 128 bits. the cache was organized into dual 2-Way Set Associative L1 cache and an 8-Way Set Associative L2 cache with an 8-way True LRU replacement policy. The L1 caches all used the same memory and also used an arbiter to avoid any overlapping between data and instructions. All of this was run on a clock with a 46ns period.
We also managed to add early branch resolution in the EX stage, a 4-Way Set Associative branch target buffer with support for unconditional branches, a skewed branch predictor, and performance counters that kept track of L1 (instruction and data misses) and L2 cache misses, branch prediction misses, and bubble insertions.
Our design also won 2nd place in the final design competition. Out of about 12 teams, only 2 (including us) managed to get their design to work on the final competition code, and we missed 1st place by a few milliseconds. Here's a picture of the pipeline:
We also managed to add early branch resolution in the EX stage, a 4-Way Set Associative branch target buffer with support for unconditional branches, a skewed branch predictor, and performance counters that kept track of L1 (instruction and data misses) and L2 cache misses, branch prediction misses, and bubble insertions.
Our design also won 2nd place in the final design competition. Out of about 12 teams, only 2 (including us) managed to get their design to work on the final competition code, and we missed 1st place by a few milliseconds. Here's a picture of the pipeline: